本文共 9502 字,大约阅读时间需要 31 分钟。
前言
Taro是凹凸实验室遵循 语法规范的多端开发方案, 目前已对外开源一段时间,受到了前端开发者的广泛欢迎和关注。截止目前 数已经突破11.2k,还在开启的 Issues 达 200多个,已经关闭700多个,可见使用并参与讨论的开发者是非常多的。Taro 目前已经支持微信小程序、H5、RN、支付宝小程序、百度小程序,持续迭代中的 Taro,也正在兼容更多的端以及增加一些新特性的支持。
回归正题,本篇文章主要讲的是 Taro 深度开发实践,综合我们在实际项目中使用 Taro 的一些经验和总结,首先会谈谈 Taro 为什么选择使用React语法,然后再从Taro项目的代码组织、数据状态管理、性能优化以及多端兼容等几个方面来阐述 Taro 的深度开发实践体验。
为什么选择使用React语法?
这个要从两个方面来说,一是小程序原生的开发方式不够友好,或者说不够工程化,在开发一些大型项目时就会显得很吃力,主要体现在以下几点:
一个小程序页面或组件,需要同时包含 4 个文件,以至开发一个功能模块时,需要多个文件间来回切换;
没有自定义文件预处理,无法直接使用 Sass、Less 以及较新的 ES Next 语法;
字符串模板太过孱弱,小程序的字符串模板仿的是 Vue,但是没有提供 Vue 那么多的语法糖,当实现一些比较复杂的处理时,写起来就非常麻烦,虽然提供了
wxs作为补充,但是使用体验还是非常糟糕;缺乏测试套件,无法编写测试代码来保证项目质量,也就不能进行持续集成,自动化打包。
原生的开发方式不友好,自然就想要有更高效的替代方案。所以我们将目光投向了市面上流行的三大前端框架React、Vue、Angular 。Angular在国内的流行程度不高,我们首先排除了这种语法规范。而类 Vue 的小程序开发框架市面上已经有一些优秀的开源项目,同时我们部门内的技术栈主要是 React,那么 React 语法规范 也自然成为了我们的第一选择。除此之外,我们还有以下几点的考虑:
React 一门非常流行的框架,也有广大的受众,使用它也能降低小程序开发的学习成本;
小程序的数据驱动模板更新的思想与实现机制,与 React 类似;
React 采用 JSX 作为自身模板,JSX 相比字符串模板来说更加自由,更自然,更具表现力,不需要依赖字符串模板的各种语法糖,也能完成复杂的处理;
React 本身有跨端的实现方案 ReactNative,并且非常成熟,社区活跃,对于 Taro 来说有更多的多端开发可能性。
综上所述,Taro 最终采用了 React 语法 来作为自己的语法标准,配合前端工程化的思想,为小程序开发打造了更加优雅的开发体验。
Taro项目的代码组织
要进行 Taro 的项目开发,首先自然要安装 taro-cli,具体的安装方法可参照文档(),这里不做过多介绍了,默认你已经装好了 taro-cli 并能运行命令。
然后我们用 cli 新建一个项目,得到的项目模板如下:
├── dist 编译结果目录├── config 配置目录| ├── dev.js 开发时配置| ├── index.js 默认配置| └── prod.js 打包时配置├── src 源码目录| ├── pages 页面文件目录| | ├── index index页面目录| | | ├── index.js index页面逻辑| | | └── index.css index页面样式| ├── app.css 项目总通用样式| └── app.js 项目入口文件└── package.json
如果是十分简单的项目,用这样的模板便可以满足需求,在 index.js 文件中编写页面所需要的逻辑。
假如项目引入了 redux,例如我们之前开发的项目,目录则是这样的:
├── dist 编译结果目录├── config 配置目录| ├── dev.js 开发时配置| ├── index.js 默认配置| └── prod.js 打包时配置├── src 源码目录| ├── actions redux里的actions| ├── asset 图片等静态资源| ├── components 组件文件目录| ├── constants 存放常量的地方,例如api、一些配置项| ├── reducers redux里的reducers| ├── store redux里的store| ├── utils 存放工具类函数| ├── pages 页面文件目录| | ├── index index页面目录| | | ├── index.js index页面逻辑| | | └── index.css index页面样式| ├── app.css 项目总通用样式| └── app.js 项目入口文件└── package.json
我们之前开发的一个电商小程序,整个项目大概3万行代码,数十个页面,就是按上述目录的方式组织代码的。比较重要的文件夹主要是pages、components和actions。
pages里面是各个页面的入口文件,简单的页面就直接一个入口文件可以了,倘若页面比较复杂那么入口文件就会作为组件的聚合文件,
redux的绑定一般也是此页面里进行。组件都放在components里面。里面的目录是这样的,假如有个
coupon优惠券页面,在pages自然先有个coupon,作为页面入口,然后它的组件就会存放在components/coupon里面,就是components里面也会按照页面分模块,公共的组件可以建一个components/public文件夹,进行复用。这样的好处是页面之间互相独立,互不影响。所以我们几个开发人员,也是按照页面的维度来进行分工,互不干扰,大大提高了我们的开发效率。
actions这个文件夹也是比较重要,这里处理的是拉取数据,数据再处理的逻辑。可以说,数据处理得好,流动清晰,整个项目就成功了一半,具体可以看下面*数据状态管理*的部分。如上,假如是
coupon页面的actions,那么就会放在actions/coupon里面,可以再一次见到,所有的模块都是以页面的维度来区分的。
除此之外,asset文件用来存放的静态资源,如一些icon类的图片,但建议不要存放太多,毕竟程序包有限制。而constants则是一些存放常量的地方,例如api域名,配置等等。
项目搭建完毕后,在根目录下运行命令行 npm run build:weapp 或者 taro build --type weapp --watch 编译成小程序,然后就可以打开小程序开发工具进行预览开发了。编译成其他端的话,只需指定 type 即可(如编译 H5 :taro build --type h5 --watch )。
使用 Taro 开发项目时,代码组织好,遵循规范和约定,便成功了一半,至少会让开发变得更有效率。
数据状态管理
上面说到,会用 redux 进行数据状态管理。
说到 redux,相信大家早已耳熟能详了。在 Taro 中,它的用法和平时在 React 中的用法大同小异,先建立 store、reducers,再编写 actions;然后通过@tarojs/redux,使用Provider 和 connect,将 store 和 actions 绑定到组件上。基础的用法大家都懂,下面我给大家介绍下如何更好地使用 redux。
数据预处理
相信大家都遇到过这种时候,接口返回的数据和页面显示的数据并不是完全对应的,往往需要再做一层预处理。那么这个业务逻辑应该在哪里管理,是组件内部,还是redux的流程里?
举个例子:
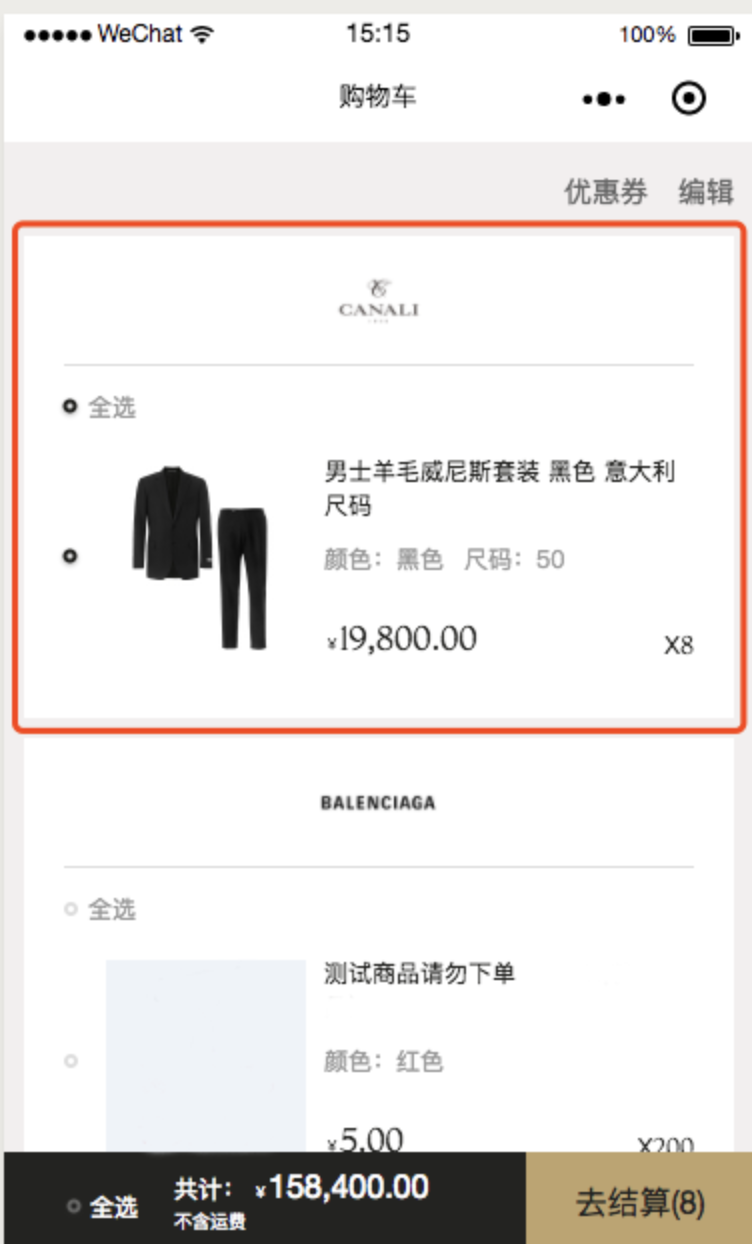
例如上图的购物车模块,接口返回的数据是:
{\tcode: 0,\tdata: { shopMap: {...}, // 存放购物车里商品的店铺信息的map goods: {...}, // 购物车里的商品信息 ...\t}\t...} 对的,购车里的商品店铺和商品是放在两个对象里面的,但视图要求它们要显示在一起。这时候,如果直接将返回的数据存到store,然后在组件内部render的时候东拼西凑,将两者信息匹配,再做显示的话,会显得组件内部的逻辑十分的混乱,不够纯粹。
所以,我个人比较推荐的做法是,在接口返回数据之后,直接将其处理为与页面显示对应的数据,然后再dispatch处理后的数据,相当于做了一层拦截,像下面这样:
const data = result.data // result为接口返回的数据const cartData = handleCartData(data) // handleCartData为处理数据的函数dispatch({type: 'RECEIVE_CART', payload: cartData}) // dispatch处理过后的函数...// handleCartData处理后的数据{ commoditys: [{ shop: {...}, // 商品店铺的信息 goods: {...}, // 对应商品信息 }, ...]} 可以见到,处理数据的流程在render前被拦截处理了,将对应的商品店铺和商品放在了一个对象了。
这样做有如下几个好处:
一个是组件的渲染更纯粹,在组件内部不用再关心如何将数据修改而满足视图要求,只需关心组件本身的逻辑,例如点击事件,用户交互等。
二是数据的流动更可控,后台数据 ——\u0026gt; 拦截处理 ——\u0026gt; 期望的数据结构 ——\u0026gt; 组件,假如后台返回的数据有变动,我们要做的只是改变
handleCartData函数里面的逻辑,不用改动组件内部的逻辑。
实际上,不只是后台数据返回的时候,其它数据结构需要变动的时候都可以做一层数据拦截,拦截的时机也可以根据业务逻辑调整,重点是要让组件内部本身不关心数据与视图是否对应,只专注于内部交互的逻辑,这也很符合 React 本身的初衷,数据驱动视图。
用Connect实现计算属性
计算属性?这不是响应式视图库才会有的么,其实也不是真正的计算属性,只是通过一些处理达到模拟的效果而已。因为很多时候我们使用 redux 就只是根据样板代码复制一下,改改组件各自的store、actions。实际上,我们它可以做更多的事情,例如:
export default connect(({ cart,}) =\u0026gt; ({ couponData: cart.couponData, commoditys: cart.commoditys, editSkuData: cart.editSkuData}), (dispatch) =\u0026gt; ({ // ...actions绑定}))(Cart)// 组件里render () {\tconst isShowCoupon = this.props.couponData.length !== 0 return isShowCoupon \u0026amp;\u0026amp; \u0026lt;Coupon /\u0026gt;} 上面是很普通的一种connect写法,然后render函数根据couponData里是否数据来渲染。这时候,我们可以把this.props.couponData.length !== 0这个判断丢到connect里,达成一种computed的效果,如下:
export default connect(({ cart,}) =\u0026gt; { const { couponData, commoditys, editSkuData } = cart const isShowCoupon = couponData.length !== 0 return { isShowCoupon, couponData, commoditys, editSkuData}}, (dispatch) =\u0026gt; ({ // ...actions绑定}))(Cart)// 组件里render () { return this.props.isShowCoupon \u0026amp;\u0026amp; \u0026lt;Coupon /\u0026gt;} 可以见到,在connect里定义了isShowCoupon变量,实现了根据couponData来进行computed的效果。
实际上,这也是一种数据拦截处理。除了computed,还可以实现其它的功能,具体就由各位看官自由发挥了。
性能优化
关于数据状态处理,我们提到了两点,主要都是关于 redux 的用法。接下我们聊一下关于性能优化的。
setState的使用
其实在小程序的开发中,最大可能的会遇到的性能问题,大多数出现在setData(具体到 Taro 中就是调用 setState 函数)上。这是由小程序的设计机制所导致的,每调用一次 setData,小程序内部都会将该部分数据在逻辑层(运行环境 JSCore)进行类似序列化的操作,将数据转换成字符串形式传递给视图层(运行环境 WebView),视图层通过反序列化拿到数据后再进行页面渲染,这个过程下来有一定性能开销。
所以关于setState的使用,有以下几个:
避免一次性更新巨大的数据。这个更多的是组件设计的问题,在平衡好开发效率的情况下尽可能地细分组件。
避免频繁地调用
setState。实际上在 Taro 中 setState 是异步的,并且在编译过程中会帮你做了这层优化,例如一个函数里调用了两次 setState,最后 Taro 会在下一个事件循环中将两者合并,并剔除重复数据。避免后台态页面进行
setState。这个更有可能是因为在定时器等异步操作中使用了 setState,导致后台态页面进行了 setState 操作。要解决问题该就在页面销毁或是隐藏时进行销毁定时器操作即可。
列表渲染优化
在我们开发的一个商品列表页面中,是需要有无限下拉的功能。
因此会存在一个问题,当加载的商品数据越来越多时,就会报错,invokeWebviewMethod 数据传输长度为 1227297 已经超过最大长度 1048576。原因就是我们上面所说的,小程序在 setData 的时候会将该部分数据在逻辑层与视图层之间传递,当数据量过大时就会超出限制。
为了解决这个问题,我们采用了一个大分页思想的方法。就是在下拉列表中记录当前分页,达到 10 页的时候,就以 10 页为分割点,将当前 this.state 里的 list 取分割点后面的数据,判断滚动向前滚动就将前面数据 setState 进去,流程图如下:

可以见到,我们先把商品所有的原始数据放在this.allList中,然后判断根据页面的滚动高度,在页面滚动事件中判断当前的页码。页码小于10,取 this.allList.slice 的前十项,大于等于10,则取后十项,最后再调用 this.setState 进行列表渲染。这里的核心思想就是,把看得见的数据才渲染出来,从而避免数据量过大而导致的报错。
同时为了提前渲染,我们会预设一个500的阈值,使整个渲染切换的流程更加顺畅。
多端兼容
尽管 Taro 编译可以适配多端,但有些情况或者有些 API 在不同端的表现差异是十分巨大的,这时候 Taro 没办法帮我们适配,需要我们手动适配。
process.env.TARO_ENV
使用process.env.TARO_ENV可以帮助我们判断当前的编译环境,从而做一些特殊处理,目前它的取值有 weapp 、swan 、 alipay 、 h5 、 rn 五个。可以通过这个变量来书写对应一些不同环境下的代码,在编译时会将不属于当前编译类型的代码去掉,只保留当前编译类型下的代码,从而达到兼容的目的。例如想在微信小程序和 H5 端分别引用不同资源:
if (process.env.TARO_ENV === 'weapp') { require('path/to/weapp/name')} else if (process.env.TARO_ENV === 'h5') { require('path/to/h5/name')} 我们知道了这个变量的用法后,就可以进行一些多端兼容了,下面举两个例子来详细阐述。
滚动事件兼容
在小程序中,监听页面滚动需要在页面中的onPageScroll事件里进行,而在 H5 中则是需要手动调用window.addEventListener来进行事件绑定,所以具体的兼容我们可以这样处理:
class Demo extends Component { constructor() { super(...arguments) this.state = { } this.pageScrollFn = throttle(this.scrollFn, 200, this) } scrollFn = (scrollTop) =\u0026gt; { // do something } // 在H5或者其它端中,这个函数会被忽略 onPageScroll (e) { this.pageScrollFn(e.scrollTop) } componentDidMount () { // 只有编译为h5时下面代码才会被编译\tif (process.env.TARO_ENV === 'h5') { window.addEventListener('scroll', this.pageScrollFn)\t} }} 可以见到,我们先定义了页面滚动时所需执行的函数,同时外面做了一层节流的处理
不了解函数节流的可以看。
然后,在 onPageScroll 函数中,我们将该函数执行。同时的,在 componentDidMount 中,进行环境判断,如果是 h5 环境就将其绑定到 window 的滚动事件上。
通过这样的处理,在小程序中,页面滚动时就会执行 onPageScroll 函数(在其它端该函数会被忽略);在 h5 端,则直接将滚动事件绑定到window上。因此我们就达成小程序,h5端的滚动事件的绑定兼容(其它端的处理也是类似的)。
canvas兼容
假如要同时在小程序和 H5 中使用 canvas,同样是需要进行一些兼容处理。canvas 在小程序和 H5 中的 API 基本都是一致的,但有几点不同:
canvas 上下文的获取方式不同,h5 中是直接从 dom 中获取;而小程序里要通过调用 Taro.createCanvasContext 来手动创建;
绘制时,小程序里还需在手动调用 CanvasContext.draw 来进行绘制。
所以做兼容处理时就围绕这两个点来进行兼容:
componentDidMount () { // 只有编译为h5下面代码才会被编译 if (process.env.TARO_ENV === 'h5') { this.context = document.getElementById('canvas-id').getContext('2d') // 只有编译为小程序下面代码才会被编译 } else if (process.env.TARO_ENV === 'weapp') { this.context = Taro.createCanvasContext('canvas-id', this.$scope)\t}}// 绘制的函数draw () { // 进行一些绘制操作 \t// ..... // 兼容小程序端的绘制 typeof this.context.draw === 'function' \u0026amp;\u0026amp; this.context.draw(true)}render () { // 同时标记上id和canvas-id\treturn \u0026lt;Canvas id='canvas-id' canvas-id='canvas-id'/\u0026gt;} 可以见到,先是在 componentDidMount 生命周期中,分别针对不同的端的方法而取得 CanvasContext 上下文,在小程序端是直接通过Taro.createCanvasContext进行创建,同时需要在第二个参数传入this.$scope;在 H5 端则是通过 document.getElementById(id).getContext('2d')来获得 CanvasContext 上下文。
获得上下文后,绘制的过程是一致的,因为两端的 API 基本一样,而只需在绘制到最后时判读上下文是否有 draw 函数,有的话就执行一遍来兼容小程序端,将其绘制出来。
我们内部用 Canvas 写了一个弹幕挂件,正是用这种方法来进行两端的兼容。
上述两个具体例子总结起来,就是先根据 Taro 内置的 process.env.TARO_ENV 环境变量来判断当前环境,然后再对某些端进行单独适配。因此具体的代码层级的兼容方式会多种多样,完全取决于你的需求,希望上面的例子能对你有所启发。
总结
本文先谈了 Taro 为什么选择使用React语法,然后再从Taro项目的代码组织、数据状态管理、性能优化以及多端兼容这几个方面来阐述了 Taro 的深度开发实践体验。整体而言,都是一些较为深入的,偏实践类的内容,如有什么观点或异议,欢迎加入开发交流群,一起参与讨论。
更多内容可关注前端之巅公众号(ID:frontshow)

转载地址:http://wnttx.baihongyu.com/